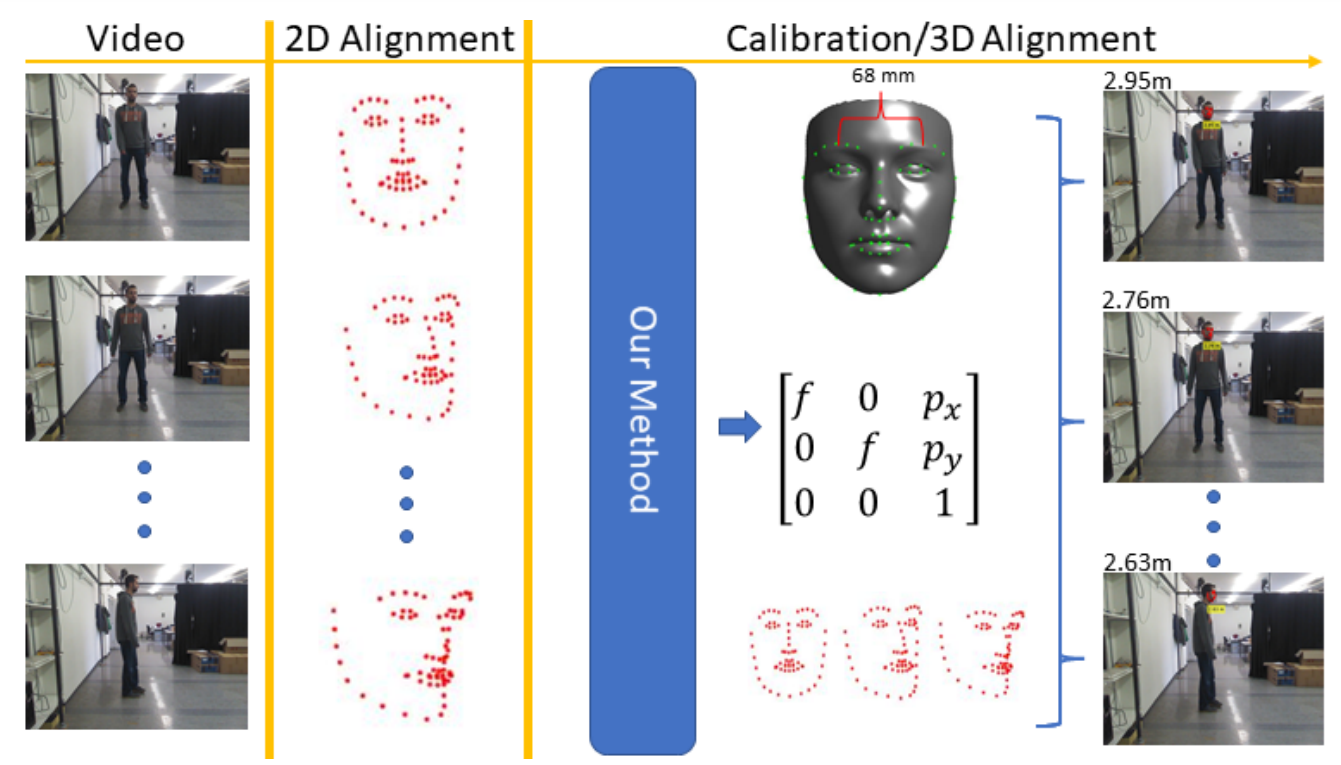
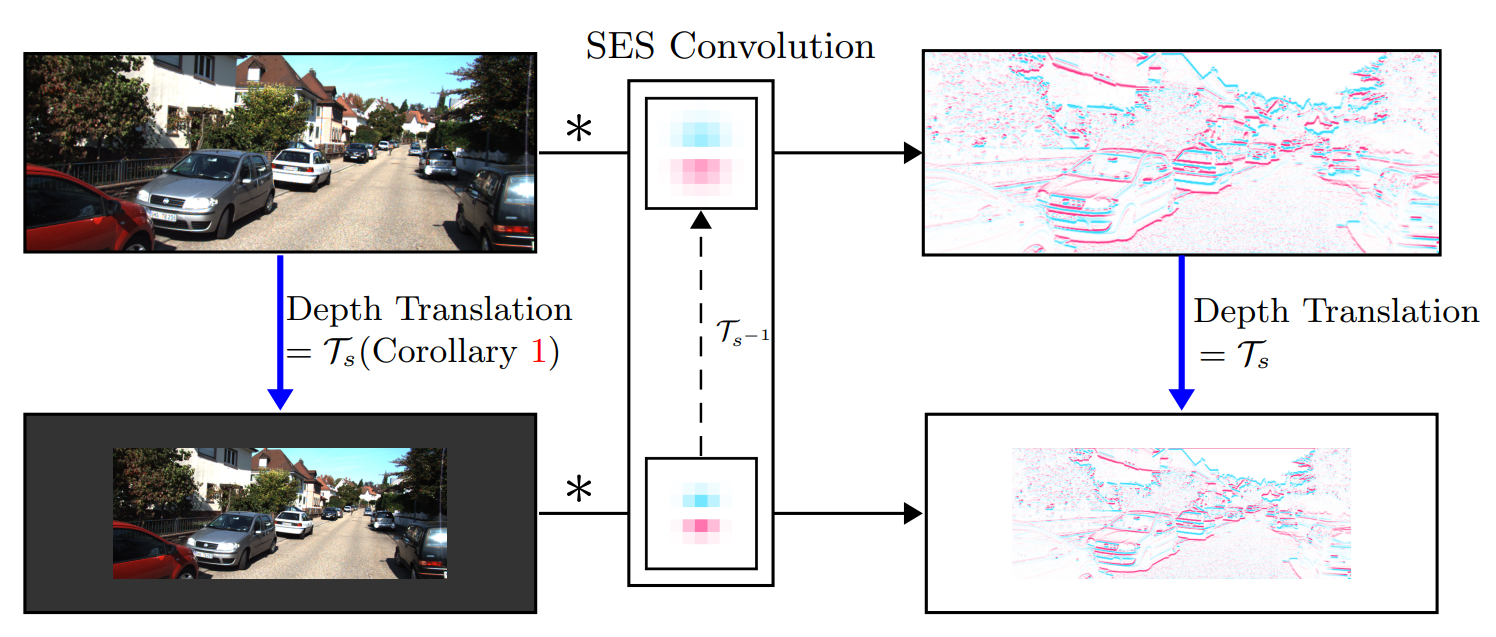
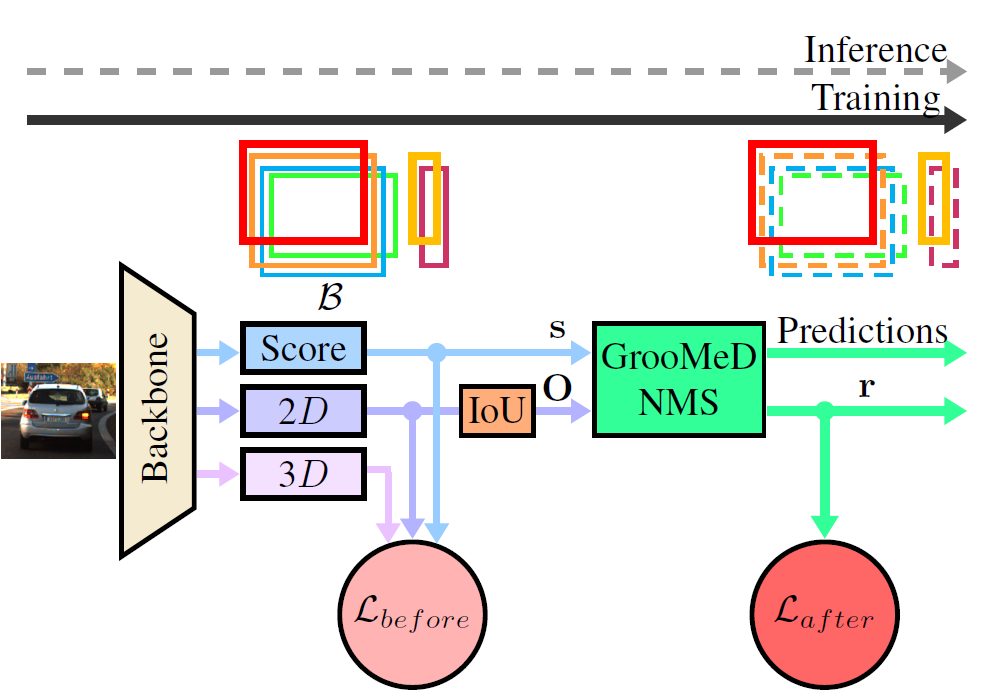
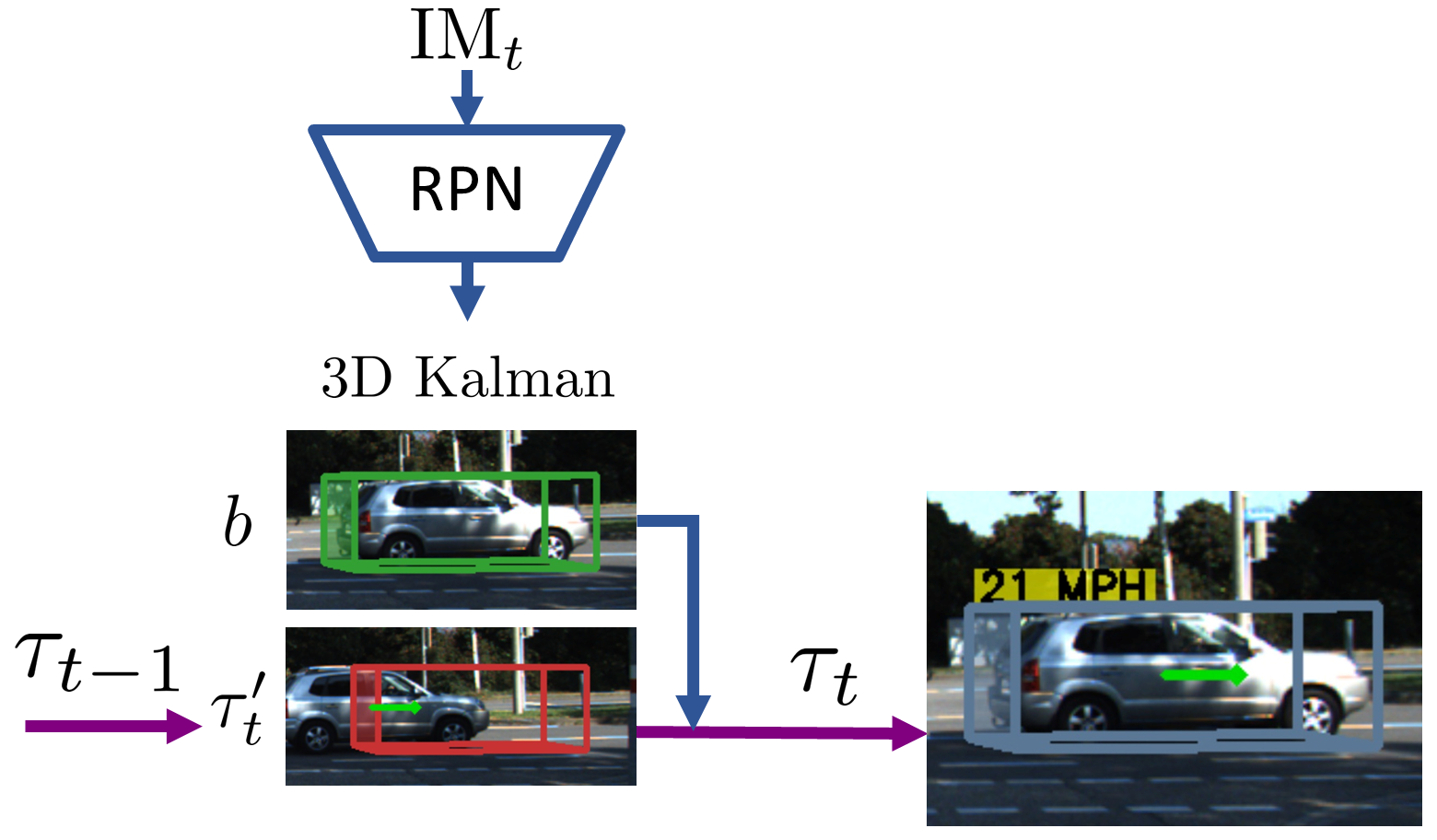
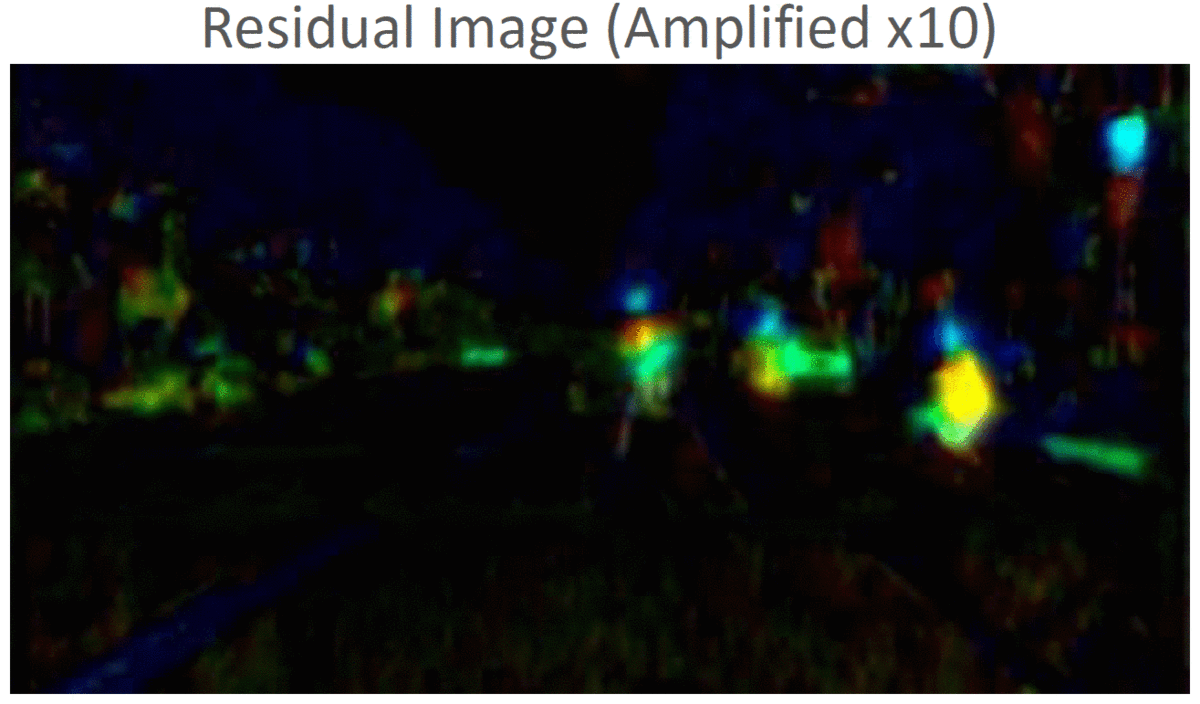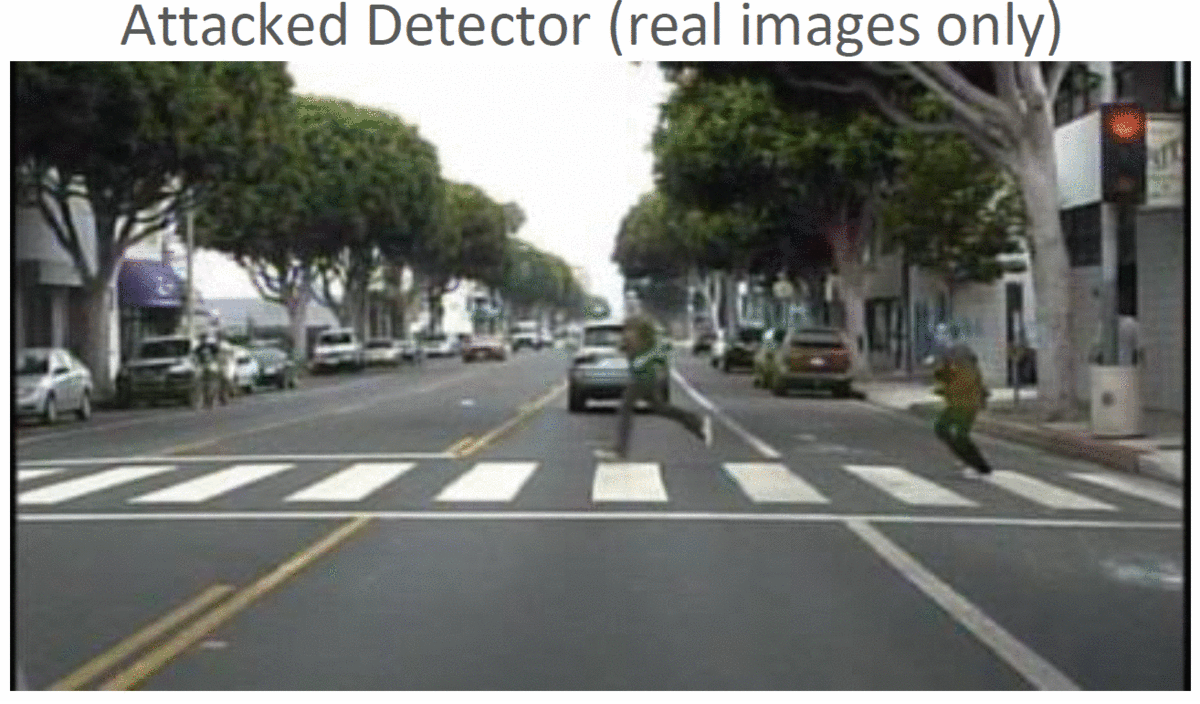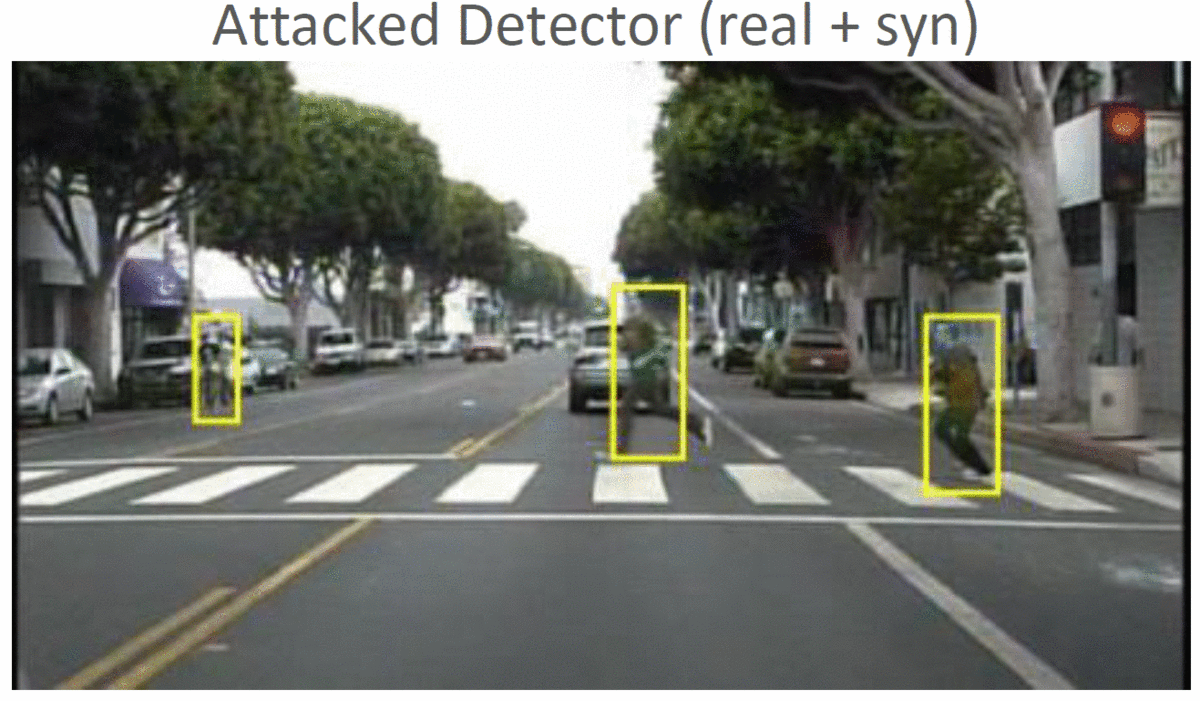
Object Detection


I work as a Senior Scientist at ROC. Before this, I worked as a postdoc researcher at FAIR in Meta. I received my PhD from Michigan State University as part of the Computer Vision Lab advised by Xiaoming Liu, with a focus on vision for self-driving cars.
I earned my bachelors in CS at Kettering University in Flint, MI.
My research interests are in computer vision and machine learning, especially in scene understanding in 2D (eg. here) or 3D and self-supervised learning.